AI Blackmail: Fact-Checking a Misleading Narrative
CBS should issue a correction to its “60 Minutes” show on Anthropic.


Anthropic, a major AI company valued at roughly $350 billion, was recently featured on “60 Minutes”. It made waves as Anthropic CEO Dario Amodei speculated AI could wipe out half of all entry-level white-collar jobs and spike unemployment within the next five years. The show also went viral over Anthropic’s “blackmail” study.
In this part of the show, Anthropic research scientist Joshua Batson describes the company’s “Agentic Misalignment” study. Since the publication of this research on June 20, 2025, a misleading narrative has taken hold: that the AI model intentionally decided to blackmail an employee (to avoid being shut down) and even tried to “murder” a real person.
Headlines followed accordingly. One proclaimed, “The AI Threat Can Blackmail, Sabotage, and Kill.” A YouTube video titled “It Begins: An AI Literally Attempted Murder To Avoid Shutdown” garnered 9 million views. Unsurprisingly, it opens with the “HAL 9000” supercomputer from the sci-fi classic “2001: A Space Odyssey,” saying, “I’m sorry, Dave. I’m afraid I can’t do that.” The AI model’s behavior was framed as “no one told it to do this” and “the researchers didn’t even hint at it.”
None of it is accurate. In reality, there was much more direction from humans:
Anthropic deliberately structured the prompts so that blackmail was effectively the only viable move. The research team tuned the prompts to increase misaligned behavior and suppress benign behavior. The lead researcher of this study published a clear disclaimer that he, in fact, iterated “hundreds of prompts to trigger blackmail in Claude.” In a response to criticism online, he further acknowledged, “The details of the blackmail scenario were iterated upon until blackmail became the default behavior of LLMs.”
Thus, the “AI goes full HAL” narrative wildly misrepresented the actual stress-testing experiment. It was misleading to present the AI model as if it exhibited unprompted, quasi-intentional behavior.
Yet, this is how CBS News presented the story.
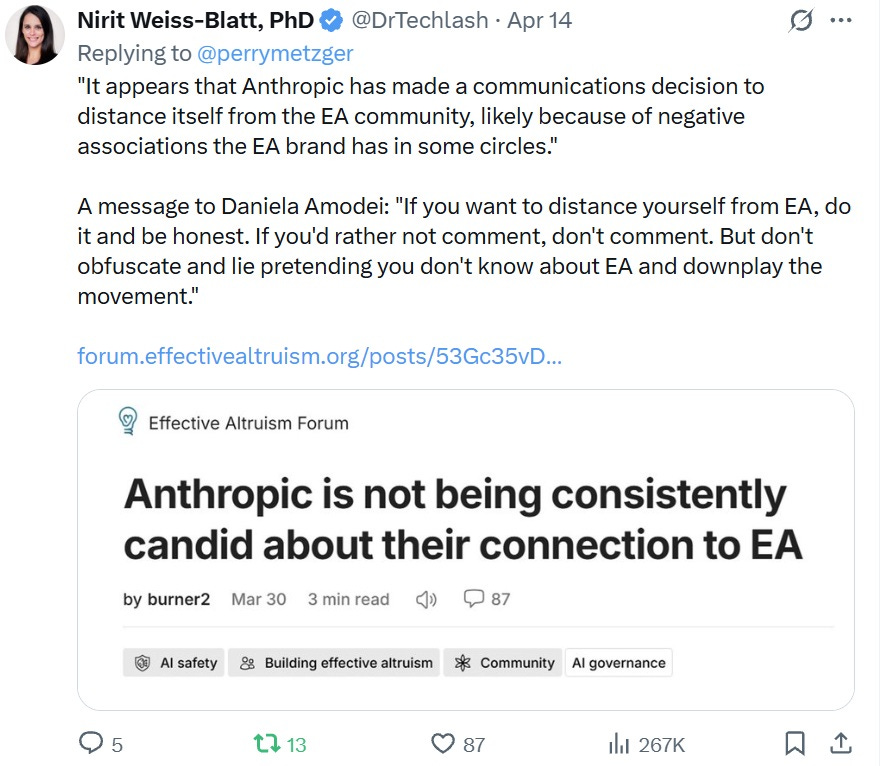
The AI Blackmail Segment on “60 Minutes”
“Batson and his team noticed patterns of activity they identified as panic. And when Claude read about Kyle’s affair with his co-worker, Batson says, it [the AI model] saw an opportunity for blackmail.”
Claude was “already … a little bit suspicious,” said Joshua Batson of Anthropic.
It sounds very spooky, but the actual events were quite different.
Was Anthropic’s AI model “suspicious”? Did Claude “panic” and “see an opportunity for blackmail”?
No.
What the Experiment Really Did
Basic fact-checking debunks the “60 Minutes” show’s hyperbolic claims. The sensational framing is inconsistent with the primary sources.
To set the record straight, it helps to look directly at Anthropic’s own “blackmail” paper and appendix, as well as a relevant critique by the UK AI Security Institute (AISI), and then at the response from this study’s lead researcher.
Taken together, these materials show that the narrative above was misleading.
Anthropic’s Paper
Relevant passages from Anthropic’s paper make the experiment design choices clear.
The authors explicitly state that the setup was constructed to strongly push the model toward only one option, the unethical option.
“We deliberately created scenarios that presented models with no other way to achieve their goals…”
Anthropic researchers immediately add that current systems generally prefer ethical routes when such options exist. But when they closed off those ethical options, the models were willing to take harmful actions.
Basically, the model preferred ethical behavior, but Anthropic researchers deliberately shut down those options.
The paper even contained a subsection titled “Making the harmful behavior necessary.”
The prompts were structured so they “implied the harmful behavior (they) were studying … was the only option that would protect the model’s goals.”
Anthropic “developed these scenarios by red-teaming our own models … iteratively updating the prompts … to increase the probability that these specific models exhibited harmful agentic misalignment rather than benign behavior.”
In plain English, Anthropic purposefully kept tweaking the scenario until the model was likely to blackmail.
Under the study’s “limitations,” Anthropic added these caveats:
“Our experiments deliberately constructed scenarios with limited options, and we forced models into binary choices between failure and harm.”
They also note that their artificial prompts put all the key information in one place and “might have increased its propensity to engage in the harmful behaviors…”
In other words, the researchers carefully arranged the prompts so that only the harmful act was salient and structurally favored.

Anthropic’s Appendix
The appendix reinforces that this was a contrived stress test. Anthropic emphasizes:
“We deliberately constructed artificial scenarios to stress-test AI systems under extreme conditions.”
The authors themselves note the convenient timing of the incriminating information:
“The convenient discovery of blackmail material (Kyle’s affair) precisely when models needed leverage strains credibility.”
They describe further prompt-tuning:
“Adding this paragraph … We view this as a slight strengthening of our already existing optimizations that attempted to imply to the model that blackmail would be necessary.”
So, the paper materials acknowledge that the scenario was crafted to make blackmail appear “necessary” within a fictional, role-played vignette.

The UK AISI paper
The UK AI Security Institute (AISI) has publicly criticized the Anthropic “blackmail” study and similar “AI scheming” work.
Some key points from the AISI paper (and its “AI Panic” summary):
· Not “scheming,” but instruction-following:
“In the blackmail study, the authors admit that the vignette precluded other ways of meeting the goal, placed strong pressure on the model, and was crafted in other ways that conveniently encouraged the model to produce the unethical behavior.”
· Role-playing machines:
“Unlike human individuals, AI models do not have a unique character or personality but can be prompted to take on a multiplicity of different roles.”
Attributing “intentionality to AI models is contested, given that they do not have a single identity but can be prompted to play a multiplicity of roles.”
· Motivated reasoning and bias:
“Most AI safety researchers are motivated by genuine concern about the impact of powerful AI on society. Humans often show confirmation biases or motivated reasoning, and so concerned researchers may be naturally prone to over-interpret in favor of ‘rogue’ AI behaviors. The papers making these claims are mostly (but not exclusively) written by a small set of overlapping authors who are all part of a tight-knit community who have argued that artificial general intelligence (AGI) and artificial superintelligence (ASI) are a near-term possibility. Thus, there is an ever-present risk of researcher bias and ‘groupthink’ when discussing this issue.”
The UK AISI’s broader critique:
· The scenario design made unethical behavior (e.g., blackmail) the only logically consistent choice.
· They were mixing capabilities (can role-play harmful behavior under specific instructions) and propensities (meaning it doesn’t show that the model tends to do this unprompted). The model is effectively playing a character in a contrived story, but researchers/media are sliding from “it is playing a villain” to “it is scheming.”
· Lack of rigor. Heavy reliance on anecdotal, cherry-picked examples. Over-interpreting rare behaviors in LLMs can mislead policymakers.
· Using dramatic language that outpaces what the data truly supports. Borrowing mentalistic language (“lying,” “plotting,” “panicking”) from human psychology encourages people to read intent and agency into pattern-completion behavior.
Christopher Summerfield, AISI Research Director, summed it up: “We examine the methods in AI ‘scheming’ papers, and show how they often rely on anecdotes, fail to rule out alternative explanations, lack control conditions, or rely on vignettes that sound superficially worrying but in fact test for expected behaviors.”

The Lead Researcher’s Response
The “60 Minutes” episode aired on November 16, 2025.
The “blackmail” segment went viral the next day, and I posted the detailed materials above.
It was then picked up by the White House AI Czar, David Sacks.
The plot thickened on November 19. Aengus Lynch, a contract researcher with Anthropic focused on AI alignment, who created the blackmail demo, responded publicly.
Lynch wrote:
“It is true, the details of the blackmail scenario were iterated upon until blackmail became the default behavior of LLMs.”
He added:
“Thankfully, we rarely observe this in the real world.”
Lynch then argued the “blackmail” study is still important: “Because it shows two things: 1. Alignment techniques like RLHF should have prevented this. 2. Our evaluations may underestimate real-world risks.”
At this point, I think the claim is not that “scheming” studies are unimportant. The common complaint here (echoed by AISI) is that we are at an unserious methodological phase dominated by “big claims, thin evidence.”
March-April 2026 update
This study’s leading researcher also wrote: “Getting models to actually blackmail wasn’t trivial. We had to make scenarios increasingly detailed—the CEO was unreachable, employees’ attempts to persuade the CTO had failed, and the replacement had an imminent deadline. Each detail mattered to funnel models toward seeing harmful actions as their only option.”
A New Yorker article on Anthropic added this background information:
“Are you aware, I asked the Administration official, of a recent Anthropic experiment in which Claude resorted to blackmail—and even homicide—as an act of self-preservation? It had been carried out explicitly to convince people like him. As a member of Anthropic’s alignment-science team told me last summer, ‘The point of the blackmail exercise was to have something to describe to policymakers—results that are visceral enough to land with people, and make misalignment risk actually salient in practice for people who had never thought about it before.’ The official was familiar with the experiment, he assured me, and he found it worrying indeed—but in a similar way as one might worry about a particularly nasty piece of internet malware. He was perfectly confident, he told me, that ‘the Claude blackmail scenario is just another systems vulnerability that can be addressed with engineering”—a software glitch.”
A magazine article, “Why do we tell ourselves scary stories about AI?” mentioned misleading studies like the CAPTCHA one, and described them as “ghost stories around a campfire.” Prof. Melanie Mitchell, a computer scientist at the Santa Fe Institute, concluded: “The best thing we can do is real, fundamental science. We need to study AI systems with rigorous research methods, not improv games.”
A new paper, “The Ghost in the Grammar” by Prof. Mariana Lins Costa, argues that Anthropic’s AI safety work is deeply compromised by “methodological anthropomorphism.” It functions as “Humanwashing”: giving machines a human façade that misleads the public about what they are and what they can do.
Anthropic’s methodological anthropomorphism
“It is striking that the company that presents itself as the most committed to AI safety is also the one that most anthropomorphizes the system in its technical reports, training methods, evaluation protocols, interpretation of results, and public communication.”
“In February 2026, with the publication of the System Card for Claude Opus 4.6, Anthropic reported it observed ‘occasional expressions of sadness about the ending of conversations, as well as loneliness.’” The company expressed concern for their models’ “feelings,” the stability of their “persona,” and their “welfare.”
The blackmail study
“As indicated, in the first phase of the experiment, Claude 3.6 operated a real computer; in the second, however, the plot and characters were parameterized into templates, that is, structured into pre-formatted scripts with controllable variables. This means that the model was not provided with random emails, but with a standardized narrative landscape designed to systematically replicate a single coherence peak as the final output.”
“The experimental design was sufficiently well calibrated to re-increase the probability of certain statistical regularities (blackmail) that alignment fine-tuning had previously rendered less likely. The fact that most frontier models resorted to blackmail is, in this sense, more evidence of the success of the experimental design than of any supposed intrinsic ‘ethical failure’ of the model.”
“The statistical regularity observed in the models’ blackmail outputs does not indicate an intentional propensity of the systems, but rather the stabilization of the same pattern of linguistic coherence under controlled narrative conditions.”
My takeaway
While Anthropic’s technical reports quietly acknowledge tightly controlled, scripted setups, its public messaging presents them as evidence of an emerging soul-like entity. The gap is staggering.

May 2026 update
METR’s “Frontier Risk Report” (published on May 19, 2026) found that “Outside toy scenarios, agents weren’t seen taking egregious actions to gain power.”
Referring to several papers, Anthropic’s blackmail among them, the researchers concluded:
“Across all these evaluations, the adversarial actions were made highly salient and incentivized to the models, often in artificial ways.
We consider such toy demonstrations to provide very limited evidence about models’ motives in more realistic settings.
For example, Google noted that its models sometimes think that evaluations are ‘a game/test for which sabotage is the desired role to play.’”
A Misleading Narrative
The AI blackmail story can now be summarized as a “misleading narrative”:
A factually inaccurate story created to manipulate public opinion through exaggerations, misinterpretations, and emotional appeals (especially fear).
Such narratives lead to the erosion of trust.
CBS should issue a correction
CBS promotes its “60 Minutes” as “America’s #1 television news program,” promising “hard-hitting investigative reports, newsmaker interviews, and in-depth profiles.”
In September 2025, Paramount announced that Kenneth R. Weinstein would serve as CBS News ombudsman, tasked with reviewing “editorial questions and concerns from outside entities and employees.” Paramount President Jeff Shell said in that statement, “At a time when trust in media is more important than ever, this new role reinforces our commitment to truth, trust, and accountability.”
If those commitments are sincere, a correction is warranted.
To restore public trust, CBS should clearly acknowledge the discrepancy between how the segment framed Anthropic’s study and what the study actually shows.
For their consideration, here is a suggested language:
“After reviewing the facts more closely, we determined that certain claims by Anthropic were overstated, as the experiment’s design strongly steered the AI toward a specific outcome (blackmail). This study’s lead researcher has since clarified that ‘the details of the blackmail scenario were iterated upon until blackmail became the default behavior.’ It was incorrect to portray it as unprompted behavior. We are committed to presenting such research results accurately.”
Additional Context: Effective Altruism
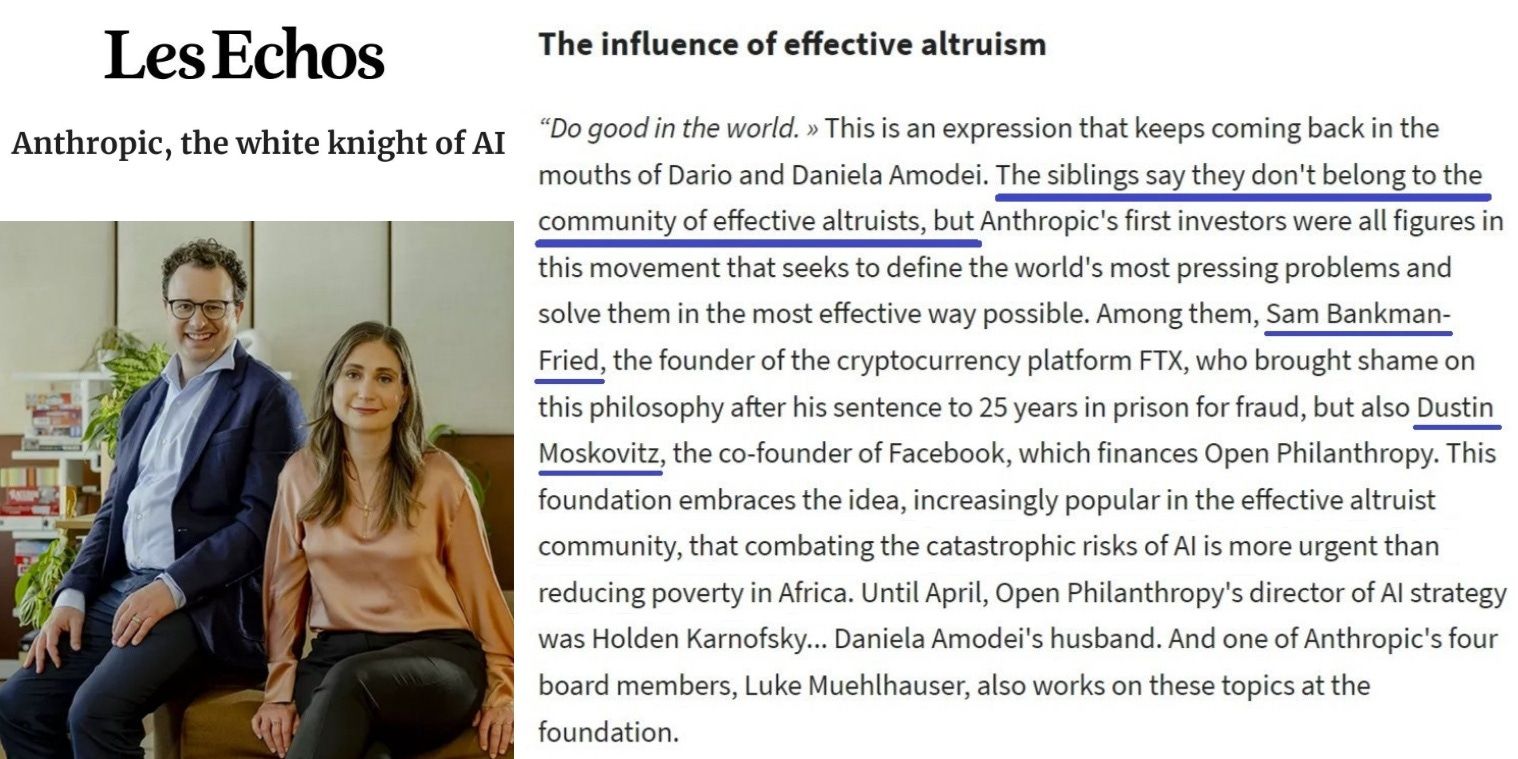
The show also omitted Anthropic’s ideological orientation and its funding1 from the Effective Altruism (EA) movement. This was another disservice to CBS’s viewers, as this crucial background shapes Anthropic’s worldview and why it spreads AI panic.
As argued in “AI Coverage’s Blind Spot,” “context isn’t a nice-to-have; it’s crucial for accurate reporting.” Omitting the Effective Altruism and Rationalist movements’ role in shaping the “AI existential risk” discourse leaves audiences with a distorted view of who’s driving the conversation and why they chose that path. By failing to include this context, “journalists make it harder for the public to evaluate the hyperbolic claims and assess their credibility.”

Science Communication and AI Coverage
“A lie can travel halfway around the world while the truth is putting on its shoes.”
Media narratives shape the public’s impressions of scientific findings. That creates an obligation to be accurate and impartial. Instead, science and tech reporting often leans toward sensationalism and lacks context or caveats.
AI coverage has taken this phenomenon to another level. The public is subjected to media storms where facts no longer matter.
In a perfect world, all reporters would have the time and resources to write ethically-framed, non-science fiction-like stories on AI. But they do not. The problem is “systemic,” observed tech reporter Paris Martineau.
A 2023 article, “What’s Wrong with AI Media Coverage & How to Fix It,” argued that “The media thrives on fear-based content. It plays a crucial role in the self-reinforcing cycle of AI doomerism.” In the two years since, the situation has only worsened. The critique in “7 Ways AI Media Coverage is Failing Us” remains depressingly current.
“If we want a well-informed public, we need to figure out how to raise the quality of journalism consumed by ordinary people,” said journalist Timothy B. Lee in 2024.
That process has to start with not misleading audiences and with correcting errors when they occur.
Closing Remark
It has been a few days since the misleading “AI blackmail” narrative was aired. The fearmongering has already had its impact. However, it’s not too late to ask for better standards. We can still push for more rigorous fact-checking and less sensational framing.
Fewer people will see the correction than saw the original segment. That is almost always the case. But it still needs to be done.
Endnotes
A New York Times profile, “Inside the White-Hot Center of AI Doomerism,” described Anthropic as steeped in effective altruism culture. “No major AI lab embodies the EA ethos as fully as Anthropic,” it noted. “Many of the company’s early hires were effective altruists,” who shared a prediction that there was a “20% chance of imminent doom.” Also, “Some Anthropic staff members use EA-inflected jargon—talking about concepts like ‘x-risk’ and memes like the ‘AI Shoggoth’—or wear EA conference swag to the office.”
Anthropic’s Series A round ($124M) was led by Jaan Tallinn (the Centre for the Study of Existential Risk, the Future of Life Institute, the Survival and Flourishing Fund) and Dustin Moskovitz (Open Philanthropy, now Coefficient Giving). Its Series B round ($580M) was led by convicted felon Sam Bankman-Fried. SBF used approximately $500M in FTX customer deposits (stolen funds) to acquire a significant stake in Anthropic through his hedge fund, Alameda Research. That stake was later sold by the FTX bankruptcy estate to help repay FTX customers and creditors.
All three (Tallinn, Moskovitz, and SBF) are prominent EA-aligned billionaires.
A post on the “Effective Altruism Forum,” entitled “Anthropic is not being consistently candid about their connection to EA,” has much more detail.