

The Doomers’ Dilemma
How to adapt to the current AI race?

2023 and 2024 were awash with unprecedented AI panic. But 2025 marks the beginning of a new trend: “Lawmakers stop worrying about AI’s existential risk and instead embrace its economic potential.”
How are the doomers coping with this new (hostile) reality? This post breaks down the recent changes in the doomers' talking points.
- How it Started

The “AI Existential Risk” ecosystem, with over a billion dollars in funding from a few Effective Altruism billionaires,1 gradually expanded to encompass hundreds of organizations (see the Map of AI Existential Safety).2 In the past few years, they gained power and propagated AI doomsaying. Many advocated extreme measures like “a strict licensing regime, clamp down on open-source models, and impose civil and criminal liability on developers” or “to remove research on powerful, autonomous AI systems away from private firms and into a highly-secure facility (the “island” idea) with multinational backing and supervision.” These authoritarian policy proposals were ultimately backlashed.
- How It’s Going
The World Has Changed: It’s AI “ACTION” Time
Instead of calling the Paris meeting “AI Safety Summit,” the French government called it the “AI Action Summit.”
The EU published a new “AI Continent Action Plan.”
The Labor Party endorsed an “AI Opportunities Action Plan” to “mainline AI in the veins” of the UK economy. UK had also rebranded its “AI Safety Institute” as the “AI Security Institute.”
JD Vance’s speeches at the “AI Action Summit” and a16z’s “American Dynamism Summit” illustrated the vibe shift: “I’m not here this morning to talk about AI safety … I’m here to talk about AI opportunity.” “We shouldn't be afraid of artificial intelligence and that, particularly for those of us lucky enough to be Americans, we shouldn’t be fearful of productive new technologies. In fact, we should seek to dominate them. And that’s certainly what this administration wants to accomplish.”
The National Institute of Standards and Technology (NIST) has issued new instructions to scientists that partner with the US Artificial Intelligence Safety Institute (AISI) to eliminate mention of “AI safety.”
One of the driving forces behind this change was the DeepSeek moment.
Wrong about China… Who? We?
A recent LessWrong post, “Why were we wrong about China and AI?” criticized the “CCP is scared of AI” narrative that dominated this community. It included various “Bad predictions on China and AI”:
Conjecture co-founder Connor Leahy: “There’s no appreciable risk from non-Western countries whatsoever,” “What the Chinese Communist Party wants is stability.”
The AI policy researcher Eva Behrens, who proposed that “The open-sourcing of advanced AI models trained on 10^25 FLOP or more should be prohibited,” also asserted that “China has neither the resources nor any interest in competing with the US in developing artificial general intelligence (AGI) primarily via scaling Large Language Models (LLMs).”
Garrison Lovely: “There is no evidence in the report to support Helberg’s claim that ‘China is racing toward AGI.’”
Control AI’s AI policy researcher Tolga Bilge: “Often a narrative is painted that China would never cooperate on AI risks, and would simply go as fast as possible, but this seems to be without much evidence” … “Cooperation between the US and China on managing AI risks seems both from obvious assumptions (neither want to bring about human extinction), and from evidence (Bletchley Declaration, and many other statements and moves by lead on both sides) to be eminently possible.”
The Center for AI Safety director, Dan Hendrycks, said that only multinational regulation will do. And with China moving to place strict controls on artificial intelligence, he sees an opening. “Normally it would be, ‘Well, we want to win as opposed to China, because they would be so bad and irresponsible,’” he says. “But actually, we might be able to jointly agree to slow down.”3 He later speculated that AI Safety regulation in the U.S “might pave the way for some shared international standards that might make China willing to also abide by some of these standards.”
The Future of Life Institute president Max Tegmark wrote, “The current Chinese leadership seems more concerned about AI xrisk than Western leaders.”
The post raised the question: “Where is the community updating? Where are the post-mortems on these failed predictions?”
Well, one “community updating” was throwing “Pause AI” under the bus.
“Pause AI”? Hell no.
“Pausing AI” is central to “The Failed Strategy of AI Doomers.” As Ben Landau-Taylor explains:
“The political strategy of the AI Doomer coalition is hopelessly confused and cannot possibly work. They seek to establish onerous regulations on for-profit AI companies in order to slow down AI research—or forcibly halt research entirely, euphemized as ‘Pause AI,’ although most of the coalition sees the latter policy as desirable but impractical to achieve.”
“Why do many people who care about AI safety not clearly endorse PauseAI?” asked a different recent LessWrong post. “Many people in AI Safety seem to be on board with the goal of ‘pausing AI,’ including, for example, Eliezer Yudkowsky and the Future of Life Institute. Neither of them is saying, ‘Support PauseAI!’ Why is that?” Among the proposed answers:
“AI safety has very limited political capital at the moment. Pausing AI just isn’t going to happen, so advocating for it makes you sound unreasonable and allows people to comfortably ignore your other opinions.”
Could it be advantageous to hide ‘maybe we should slow down on AI’ in the depths of your writing…?”
At the end of the spectrum, you have the StopAI and “Shut it all down” doomers. They are not hiding anything. As Eliezer Yudkowsky’s MIRI explained:
“Many other organizations are attempting the coalition-building, horse-trading, pragmatic approach. In private, many of the people who work at those organizations agree with us, but in public, they say the watered-down version of the message.”

“We call for what we think is needed — no more, no less. If we say we need an international halt to the development of advanced general AI systems, and that it might need to last decades, it’s because we don’t think anything less will do.
We don’t play 4-D chess. We don’t conceal our true intentions.”
What ended up happening is quite amusing, to be honest. For example: In the wake of losing the SB-1047 fight, Dan Hendrycks, the Center for AI Safety founder, tried to position himself as a “centrist.” Instead of his known 80% probability of DOOM, Hendrycks published a new policy proposal positioning himself in the middle. “Hey, look, there are bigger doomers like those at PauseAI.” Understandably, the PauseAI activists were unhappy with this distinction, complaining he was “throwing the doomer brand to the wolves.”
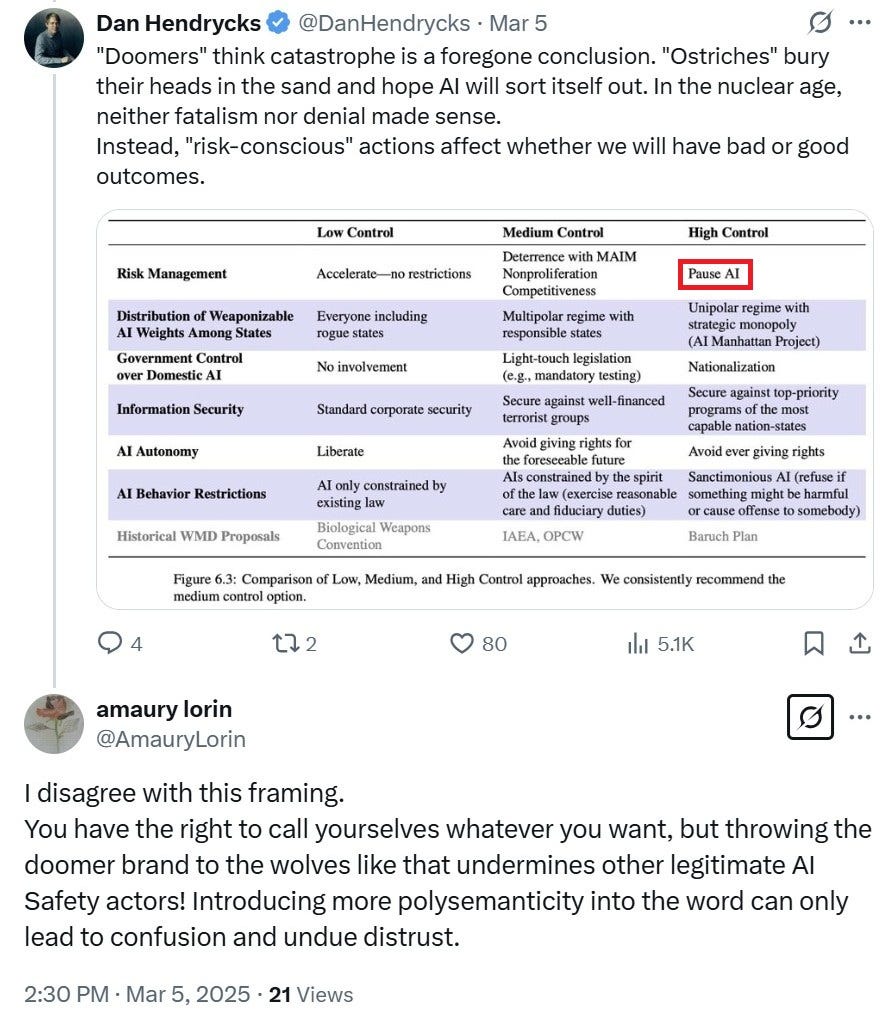
Continually moving the goalposts: Hendrycks also clarified that the current AI models are nothing to worry about. Yeah, indeed. But the internet has documentation of CAIS lobbying to effectively ban previous models.

“National Security” Sounds Better
AI Safety proposals used to have the words “existential risk” and “human extinction” tens of times throughout the text. Whenever the word “superintelligence” was used, it was accompanied by typical “x-risk” jargon. Then, AI x-risk organizations learned how to appeal to politicians. In the “Superintelligence Strategy,” for example, Dan Hendrycks was more careful. The words “extinction” and “existential” appeared only once. The new phrase (used tens of times) was “catastrophic dual-use AI.”
The bigger trend is that in order to stay relevant, AI safety groups emphasize the “National Security” angle. What didn’t work with “extinction” talking points will work with “security” talking points. NatSec risks are more grounded in reality, so they can be used to justify previous authoritarian proposals with renewed urgency.
“The AI Doomers’ plans are based on an urgency which is widely assumed but never justified,” pointed out Ben Landau-Taylor. “For many of them, the urgency leads to a rush to do something—anything—even if their strategy is unsound and has historically done exactly the opposite of what they profess to want.”
It is this rush to “do something—anything” that leads to “by all means necessary.”
Further Down the Rabbit Hole: Radicalization
A major problem with the AI doomers’ mindset of “the end justifies the means” is that all possible radical “solutions” are on the table. Why stop with pervasive surveillance of software and hardware if the government can also surveil all known AI researchers?
This is how it plays out: They start with weird ideas like “Patent trolling to save the world,” “don’t build AI or advance computer semiconductors for the next 50 years,” or that “using an open-source model” should lead to “20 years in jail.” But, then, they end up playing with dangerous ideas about “AGI developers” having “a bullet put through their head.” “Walk to the labs across the country and burn them down. Like, literally. That is the proper reaction.”
This radicalization process can only lead to bad outcomes.
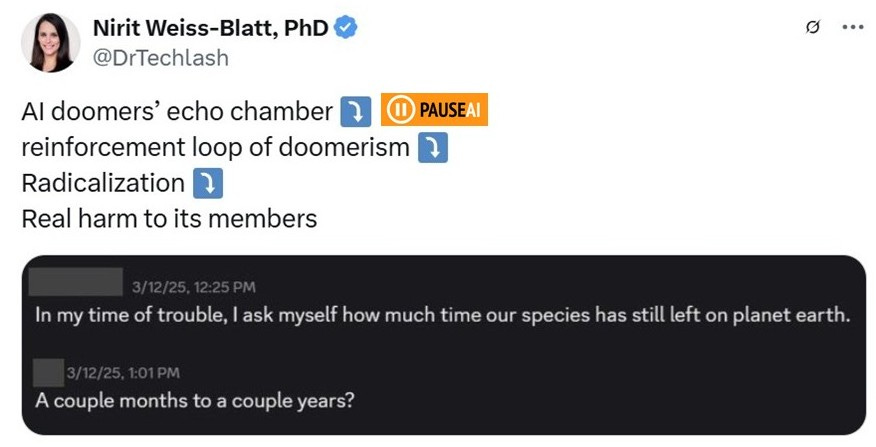
If human extinction from AI is just around the corner, based on their logic, their suggestions are “extremely small sacrifices to make.” “People like Eliezer [Yudkowsky] are annoyed when people suggest their rhetoric hints at violence against AI labs and researchers. But even if Eliezer & co don’t advocate violence, it does seem like violence is the logical conclusion of their worldview - so why is it a taboo?” … “If preventing the extinction of the human race doesn’t legitimize violence, what does?”
Another problem is that the doomers base their proposals on philosophical thought experiments and hypothetical made-up futures. The fact that they convinced themselves that their “AI existential risk” belief is the “central truth” and urgent—doesn’t make it so.
Beyond AI Hype & AI Panic: A Call for AI Realism
We need a middle-ground approach: steering the AI discourse away from the extremes.
“The debate surrounding this new technology either wildly overhypes the benefits or hyperbolically catastrophizes the potential dangers” … “There’s a large greyscale between utopian dreams and dystopian nightmares.”
- Yours truly, Generative AI isn’t our gateway to heaven nor a Frankenstein monster, The Daily Beast.
“What is needed is a rejection of both apocalyptic fear and unlimited hope. What is most urgent is a balanced, enterprising optimism—an ambitious and clear vision for what constitutes the good in technology, coupled with the awareness of its dangers.”
- Brendan McCord, Existential pessimism vs. Accelerationism: Why tech needs a rational, humanistic "Third Way", Cosmos Institute.
“People love to spin tales of AI doom or AI utopia, but it’s time to take a realistic look at AI” … “The biggest problem is not whether we need more utopias or dystopias. What we most desperately need is a heavy dose of realism.”
- Daniel Jeffries, The Middle Path for AI, Future History.
“The United States is beginning to see through the wild exaggerations about AI, both utopian and apocalyptic. That’s a welcome development. Science fiction is no foundation for serious policymaking.”
- Brian Chau, Apocalyptic predictions about AI aren’t based in reality, City Journal.
“We must move away from binary tales of catastrophe, not towards naïve utopianism that ignores problems and risks that come with change, but hopeful solutionism that reminds us we can solve and mitigate them.”
- Louis Anslow, Black Mirror’s pessimism porn won’t lead us to a better future, The Guardian.
Endnotes
The “AI Existential Risk” ecosystem grew, in part, thanks to Dustin Moskovitz, Jaan Tallinn, Vitalik Buterin, and Sam Bankman-Fried (yes, the convicted felon).
Open Philanthropy donated approximately $780 million.
Jaan Tallinn’s SFF (The Survival and Flourishing Fund) donated approximately $117 million.
In March 2024, we found out that the Future of Life Institute (FLI) reported to the IRS that it had converted a cryptocurrency donation (Shiba Inu tokens from Buterin) to approximately $665 million (using FTX/Alameda Research).
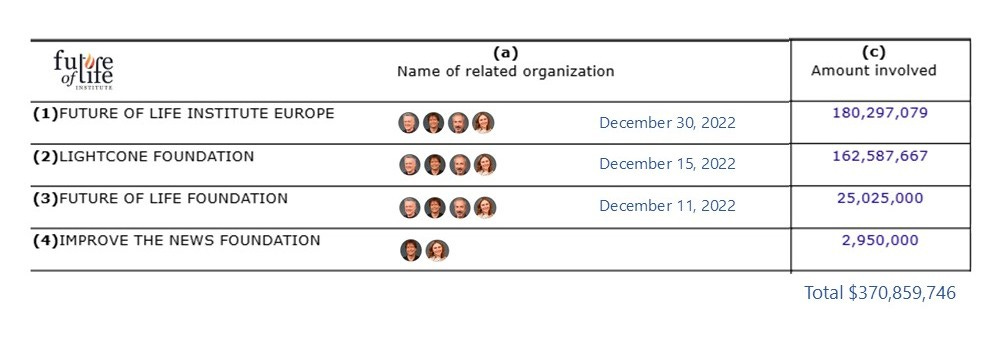
According to its new IRS Form 990, the Future of Life Institute transferred over $370M to FLI-affiliated organizations. The swift redistribution of assets included:
· December 30, 2022: FLI US transferred $180.3 million to FLI Europe (FLIE)
· December 15, 2022: FLI transferred $162.6 million to the Lightcone Foundation (LF)
· December 11, 2022: FLI transferred $25 million to the Future of Life Foundation (FLF)
In addition, FLI also donated ~$3 million to another related organization: Improve The News Foundation (Verity).
All four organizations share the same governing quartet: Max Tegmark, Meia Chita-Tegmark, Anthony Aguirre, and Jaan Tallinn.
So, 4 FLI-affiliated entities received $370.8 million. Those 4 transfers accounted for nearly the entirety of FLI’s $372.8 million in grant expenses for 2022.

The Future of Life Foundation: The initial transfer from FLI to FLF in 2022 was $25,025,000. Since then, FLI has given FLF an additional $15,681,663 in 2023 and $18,086,154 in 2024. So, the total comes to $58,792,817.
Lightcone Foundation: The initial transfer from FLI to Lightcone Foundation in 2022 was $162,587,667. Since then, there has been a two-way flow between them: FLI reported sending $6,511,558 to Lightcone (in 2023) and receiving $25,300,000 from Lightcone (in 2023 and 2024).
There are various types of AI safety organizations and AI safety work. The “AI Existential Risk” map encompasses all types. This post focuses on the loudest voices and the edges, as is the case with other movements, the edges are responsible for the worrisome behavior. Not a lot of people are aware of what’s happening there, but they should be.
June 2, 2025 update: An additional quote.
You may be interested to see my NYTimes piece from Dec 2023 about this:
Should A.I. Accelerate? Decelerate? The Answer Is Both.
https://www.nytimes.com/2023/12/10/opinion/openai-silicon-valley-superalignment.html
So do you think AI can or cannot exceed human intelligence? And if it does exceed human intelligence, do you think humans will nonetheless still be in charge of their own affairs?