

The Role of AI Metaphors in Shaping Regulations


Introduction
Artificial Intelligence (AI) is discussed in the media and policymaking with many definitions. The discourse is full of AI framings, metaphors, and analogies, many of which are non-scientific terms (“Godlike AI,” I’m looking at you).
Future-oriented terms such as “AGI” (Artificial General Intelligence), “Superintelligence,” and “Human-level AI” all suffer from definitional ambiguity. They are used both inconsistently and interchangeably with one another.1 The same goes for “Advanced AI,” “Transformative AI,” or “Frontier AI.” They are naturally the subject of debate. See, for example, “The harms of terminology: Why we should reject so-called ‘Frontier AI’.”2
The AI Safety movement, in particular, has been increasingly “using too much jargony and sci-fi language.”3 Meanwhile, its members have become more politically active. So, it turns out to be crucial to determine What term to use for AI in different policy contexts.
AI metaphors and policymaking
In order to help better organize the AI analogies and their policy implications, an in-depth review was published by an Effective Altruism (EA) organization focused on “AI Existential Risk” (x-risk).
The rationale behind it was that “Metaphors matter.”
“It matters to get clarity, because terminological and analogical framing effects happen at all stages in the cycle from technological development to societal response […] Moreover, they can shape both the policymaking processes, and the downstream judicial interpretation and application of legislative texts.”
It was shared on the Effective Altruism Forum as follows:
“You might find this useful if: you’d like to have a better primer for understanding when an AI (policy) argument strongly relies on analogies; what that does, and what other framings could be picked (and are being advanced).”
Its author shared: “Beyond endless debate over what is the ‘right’ frame for AI, there is the question of what different analogies *do*.” The policy implications in his paper are “in terms of which issues they foreground, which policy levers they highlight.”
The paper’s tables (below) contain notable policy implications. For example:
Foundational model is an effective term for “developer liability.”
Agent is an effective term for “diffusion of power away from humans.”
Frontier model implies “new risks because of new opportunities for harm, and less well-established understanding by research community. Broadly, implies danger and uncertainty but also opportunity; may imply operating within a wild, unregulated space, with little organized oversight.”
Driver of global catastrophic or existential risk: “Potential catastrophic risks from misaligned advanced AI systems or from nearer-term ‘prepotent’ systems; questions of ensuring value-alignment. Questions of whether to pause or halt progress towards advanced AI.”
Policymakers should grasp that the terms used by EA-affiliated groups and AI Safety organizations likely have this subtext.
The paper also shows that metaphors “can shape perceptions of the feasibility of regulation by certain routes”:
“Different analogies or historical comparisons for proposed international organizations for AI governance—ranging from the IAEA and IPCC to the WTO or CERN—often import tacit analogical comparisons (or rather constitute ‘reflected analogies’) between AI and those organizations’ subject matter or mandates, in ways that shape the perceptions of policymakers and the public regarding
- which of AI’s challenges require global governance;
- whether or which new organizations are needed;
- and whether the establishment of such organizations will be feasible.”
“The aim should not be to find the ‘correct’ metaphor for AI systems,” says the author of this report. “Rather, a good policy is to consider when and how different frames can be more useful for specific purposes, or for particular actors and/or (regulatory) agencies.”
This is why I’m sharing this “AI terminology explainer” with you.
I hope that the next time you see the various AI terms, you’ll think about their meaning and their “specific purpose.”
Who made this report?
The “AI metaphors and why they matter for policy” paper was published by the Legal Priorities Project (recently rebranded as the Institute for Law & AI).
It was written by Matthijs Mass, Senior Research Fellow at the Legal Priorities Project (LPP), Research Affiliate at the Centre for the Study of Existential Risk (CSER), and Associate Fellow at the Leverhulme Centre for the Future of Intelligence (CFI), University of Cambridge.
The LPP was introduced as “a new EA organization” at the Effective Altruism forum. “The idea was born at the EA group at Harvard Law School.” Cullen O’Keefe, who was a Founding Advisor and Research Affiliate at the LPP, worked in various legal and policy roles at OpenAI, and is now the Director of Research at LawAI, commented: “LPP is actually an outgrowth of the ‘Effective Altruism & Law’ Facebook group.”
This organization was described as follows on the Effective Altruism Forum and 80,000 Hours (an Effective Altruism organization):
“The Legal Priorities Project is an independent global research and field-building project founded by researchers at Harvard University. They conduct strategic legal research that aims to mitigate existential risk and promote the flourishing of future generations, and build a field that shares these priorities. They currently focus primarily on law and governance questions related to artificial intelligence.”
Funding: Effective Altruism organizations
According to its public IRS filing, the LPP received $2,365,544 in 2020-2022.
EA Funds, Long-Term Future Fund (which focuses on x-risk) shared the following justification for its grant in 2021: “The goal of the LPP is to generate longtermist legal research that could subsequently be used to influence policymakers in a longtermist direction.” Their research agenda was “well written” and “presented ‘weird’ longtermist concepts in a manner unlikely to be off-putting to those who might be put off by much of the rhetoric around such concepts elsewhere.” The LPP would lend “academic credibility to such [longtermist] ideas.”
A trio of well-known Effective Altruism billionaires donated to the Legal Priorities Project:
In 2022, Sam Bankman-Fried’s FTX Future Fund gave it $1,317,500.
In 2023, Dustin Moskowitz’s4 Open Philanthropy gave it $279,000.
Jaan Tallinn, who founded and funded the Centre for the Study of Existential Risk (CSER) and the Future of Life Institute (FLI), donated through his Survival and Flourishing Fund (SFF): $483,000.5
Jaan Tallinn recently shared his proposals for regulatory interventions: Ban training runs, surveil software, and make GPUs (above a certain capability) illegal.
Rebranding: From LPP to LawAI
The Legal Priorities Project (LPP) was recently rebranded as the Institute for Law & AI (LawAI). The rebranding didn’t change its Federal Tax Identification Number (EIN 85-1024198), but it did change its description. The institute no longer uses the phrase “aims to mitigate existential risk and promote the flourishing of future generations” but instead states:
“RESEARCH: We engage in foundational research at the intersection of law and artificial intelligence, to further our understanding of promising paths to beneficial AI governance. Current projects include work on the role of compute thresholds for AI governance, liability for harms from frontier AI systems, how to design unusually adaptive regulation, the track record of anticipatory regulation, what existing authorities US agencies currently have to regulate transformative AI, and the legal implementation of potential international institutions for AI.
CONSULTING: We advise and conduct analyses for governments, international organizations, and other public institutions as well as private actors concerning the legal challenges posed by artificial intelligence.”
According to the Founders Pledge, “Legal professionals trained by LawAI have gone on to positions of policy influence, and LawAI itself has provided valuable guidance to legislators and policymakers at the national and international level.”
AI analogies <with> policy implications
The 55 terms are organized into five groups:6
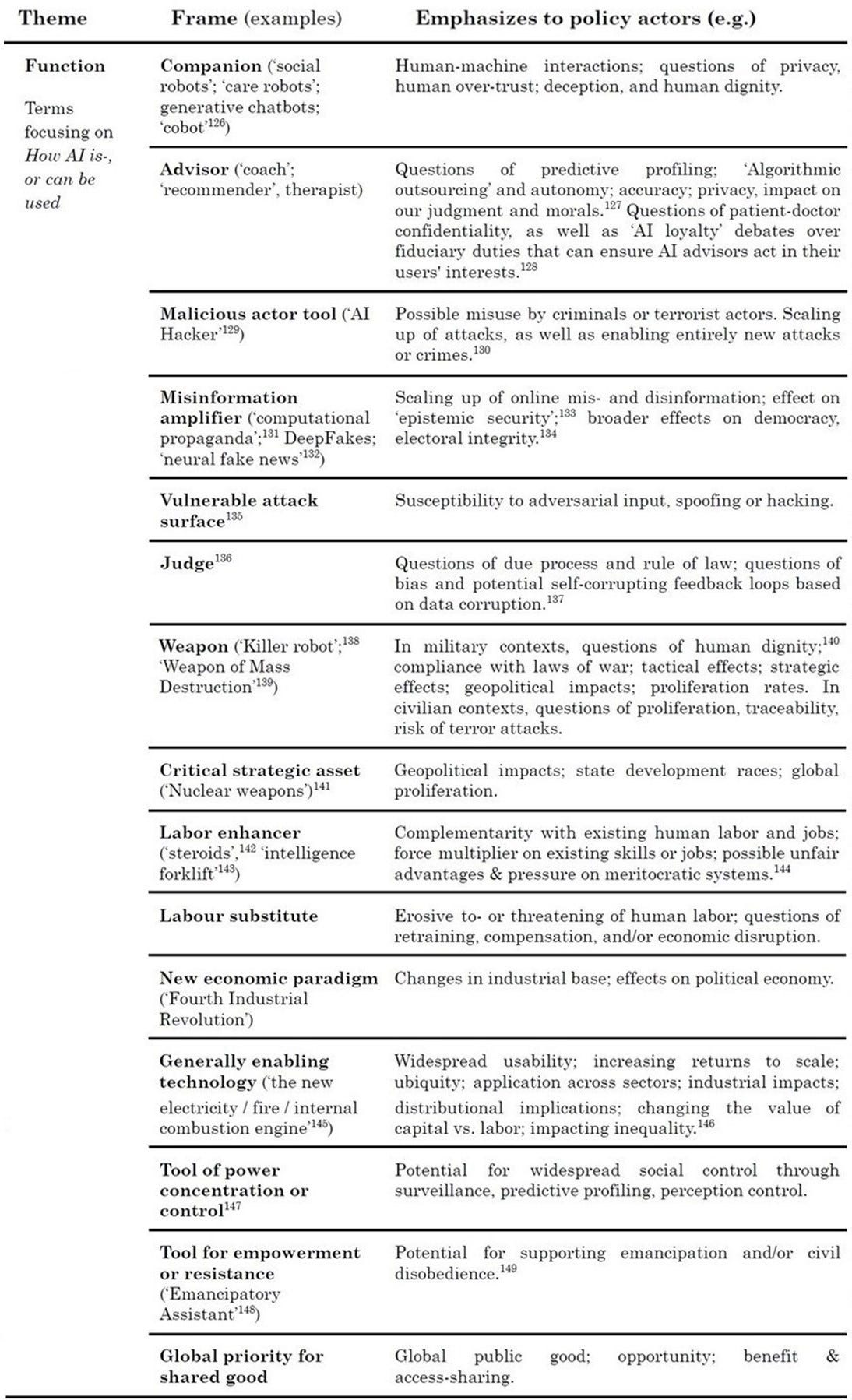
1. Essence: The nature of AI - what AI ‘is.’
2. Operation: AI’s operation - how AI works.
3. Relation: Our relation to AI - how we relate to AI as possible subject.
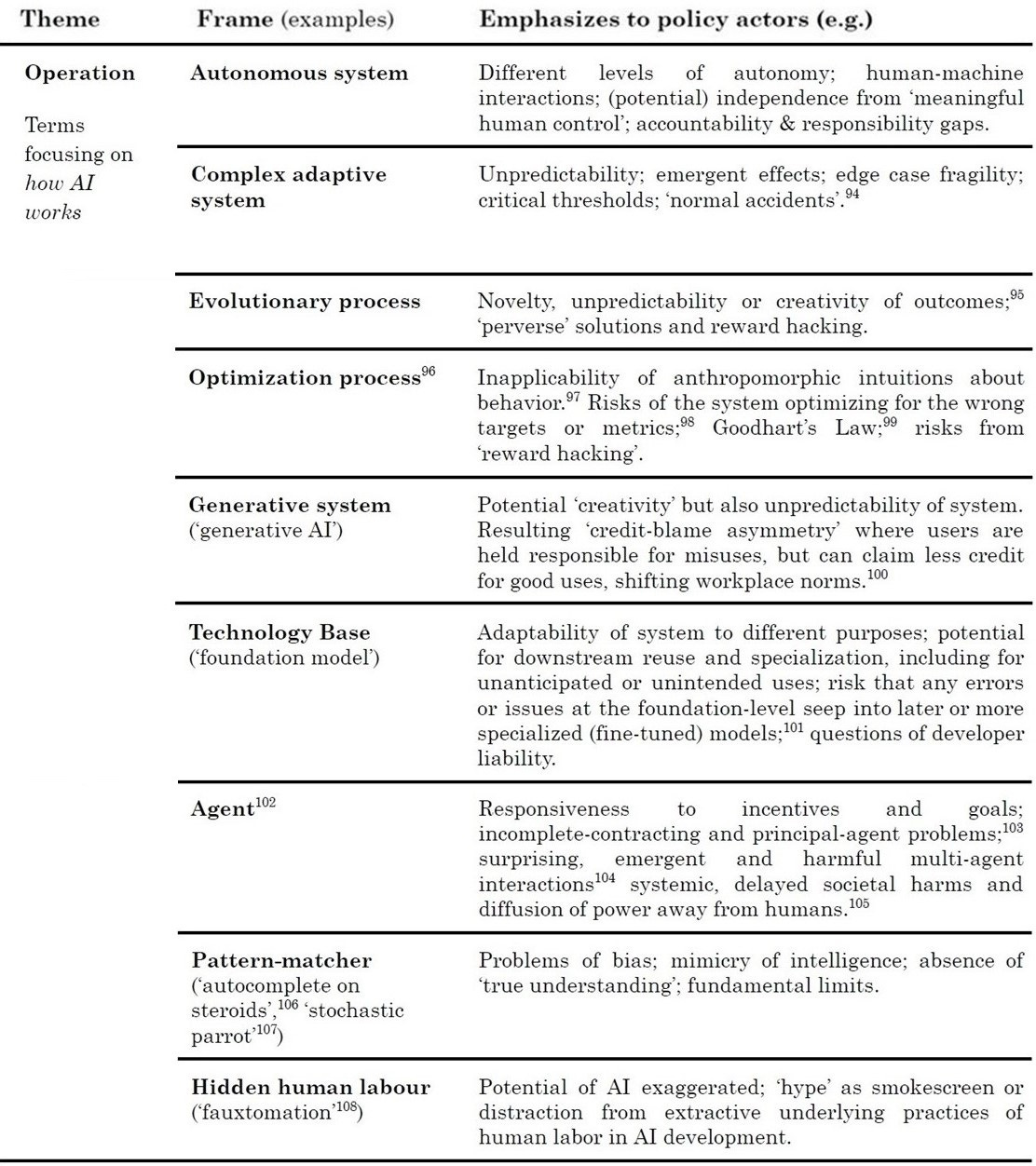
4. Function: AI’s societal function - how AI systems are or can be used.
5. Impact: AI’s impact - the unintended risks, benefits, and other side-effects of AI.
Essence: The nature of AI (what AI ‘is’) + policy implications
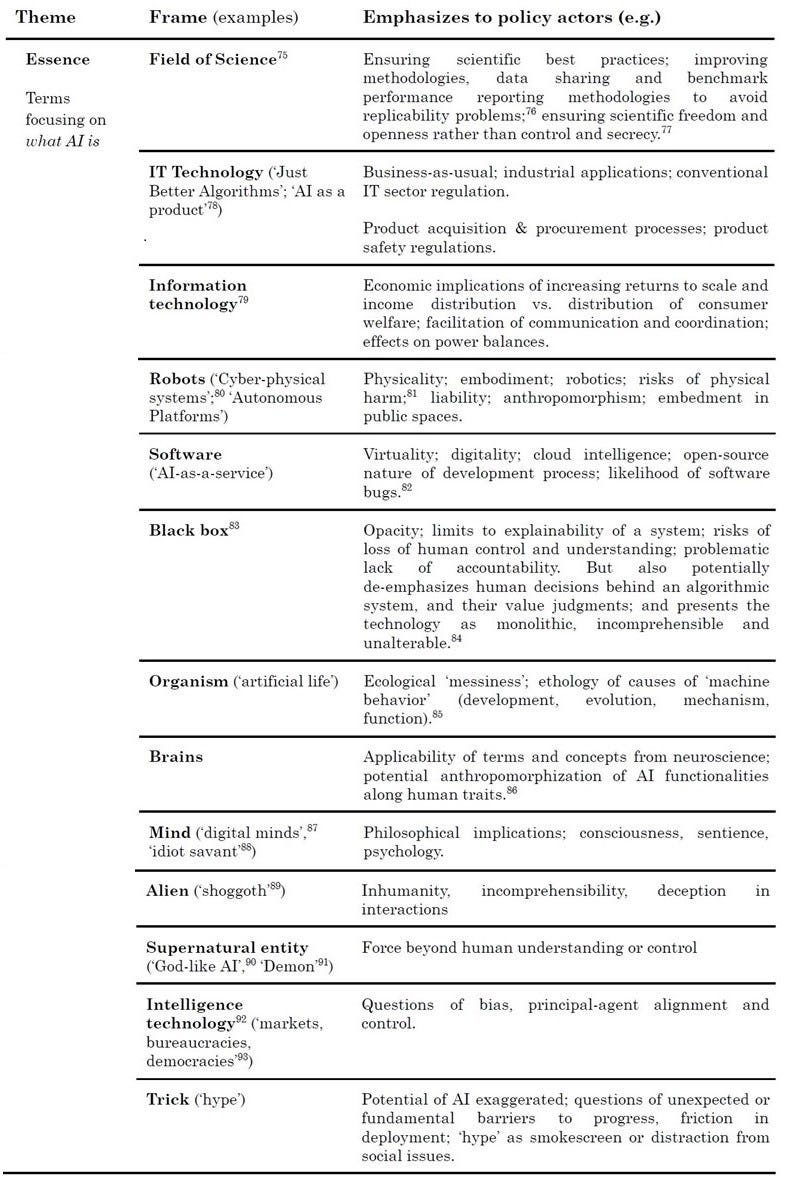
Operation: AI’s operation (how AI works) + policy implications
Relation: Our relation to AI (how we relate to AI as possible subject) + policy implications

Function: AI’s societal function (how AI systems are or can be used) + policy implications
Impact: AI’s impact (the unintended risks, benefits, and other side-effects of AI) + policy implications

Conclusions
The paper suggests a focus on “developing better processes for analogizing” and evaluating these analogies with questions like:
“What are the regulatory implications of these different metaphors? In terms of
- the coalitions they enable or inhibit,
- the issue and solution portfolios they highlight,
- or of how they position the technology within (or out of) the jurisdiction of existing institutions?”
“The hope is that this report can contribute foundations for a more deliberate and reflexive choice over what comparisons, analogies, or metaphors we use in talking about AI,” concludes the author, “and for the ways we communicate and craft policy.” (“We” = people from AI Safety/existential risk).
Recent example
Yoshua Bengio published a new paper (release on June 4, 2024): Government Interventions to Avert Future Catastrophic AI Risks. It’s a revised7 transcription of his testimony in front of the US Senate on the topic of oversight of AI.
In it, he uses the term “Superhuman” 13 times, as “superhuman AI,” “superhuman AGI” and “rogue superhuman AI.” “AGI” and “rogue AI” appear separately several times. Then, he suggested the possibility, “which could emerge in as little as a few years,” of “loss of control.”8
This grandiosity was used to propose the following regulatory interventions:
“Limiting who and how many people and organizations have access to powerful AI systems.”
“Banning powerful AI systems that are not convincingly safe” (e.g., “What are the system’s goals,” “How aligned are they with societal values?”).
“Monitoring and, if necessary, restricting sources of potential leaps in AI capabilities, like algorithmic advances, increases in computing power, or novel and qualitatively different datasets.”
Closing remark
Hopefully, people will read this terminology (“rogue superhuman AI”) with a critical eye, as it is being used to justify draconian regulatory interventions.9
We should further debate those AI terms.
“If our threat model is unrealistic, our policy responses are certain to be wrong.”10
Endnotes
Terms for “Advanced AI”: The Legal Priorities Project (LPP) defined “Advanced AI” as follows:
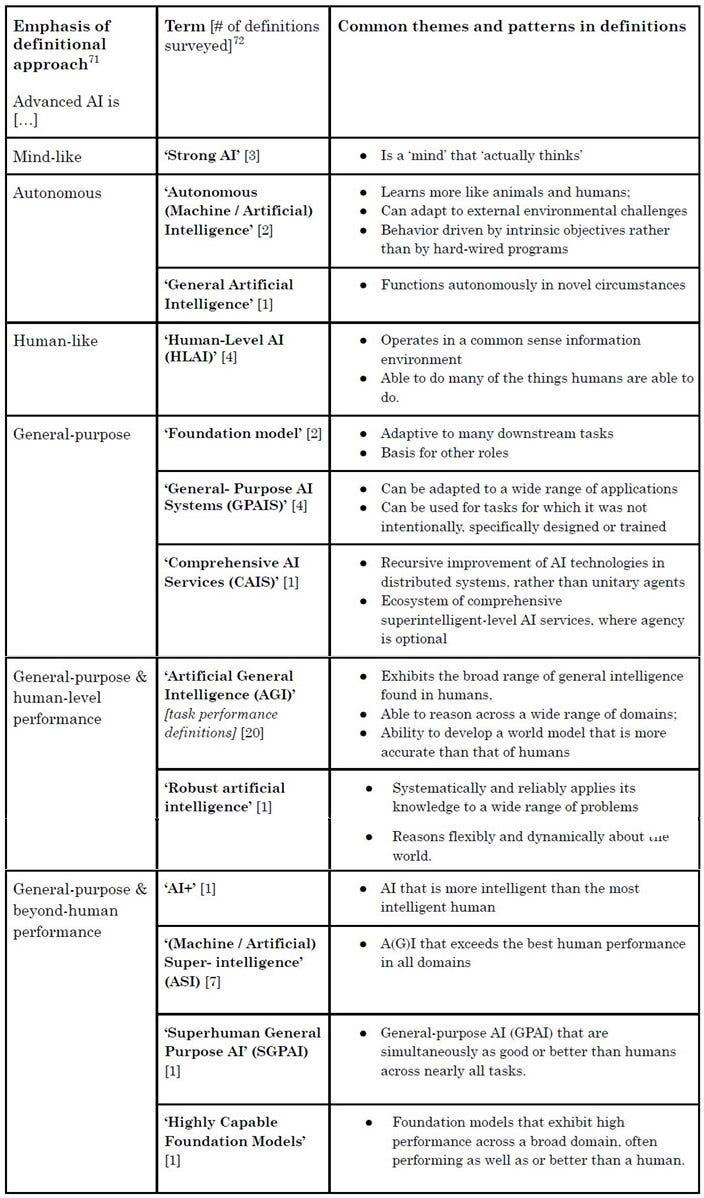
Source: Concepts in advanced AI governance (Matthijs Maas, 2023)
This paper is part of the AI & Ethics Journal’s special collection: “The Ethical Implications of AI Hype: Examining the Overinflation and Misrepresentation of AI Capabilities and Performance” (Disclaimer: I was this special issue’s Advisor). I also recommend: Talking existential risk into being: a Habermasian critical discourse perspective to AI hype.” It claims that relying on “x-risk based on AGI” is misleading. It fails in all three validity claims: Scientific validity, normative validity, and truthfulness.
The most sci-fi language can be found in the Campaign for AI Safety (CAIS). This organization aims to create “urgency around AI danger.” In 2023, it conducted “AI doom prevention message testing.” It examined which AI description would make people more fearful of AI (labeled as concern) and more willing to support a global AI moratorium (labeled as stop AI labs). CAIS collected 37 AI descriptions from “multiple people in the field of AI Safety Communications”:

It’s one thing if the “Campaign for AI Panic” remained this silly. But as it sought to influence policymakers, it became more sophisticated.
I recommend reading “Moskowitz replaces SBF as top Effective Altruism funder focused on colleges” by Annie Massa and Immanual John Milton (Bloomberg). “There are a lot of people who come into EA very driven at this point by all the cash that’s rolling around.” It describes “a culture of free-flowing funding with minimal accountability focused on selective universities.”
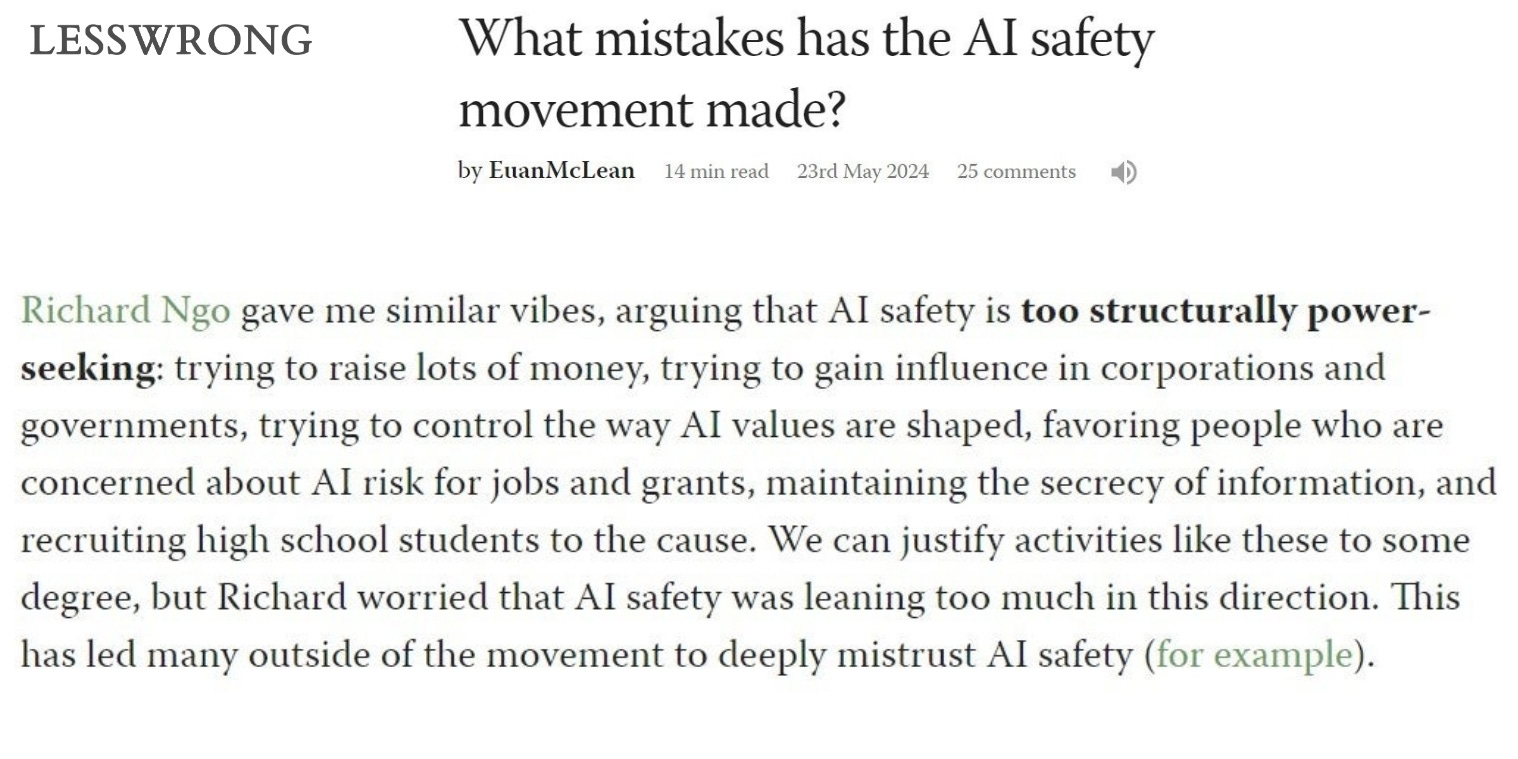
Related is this description of how AI Safety is “too structurally power-seeking“:
Detailed grants:
The LPP’s 990 forms: $156,499 in 2020, $750,428 in 2021, and $1,458,617 in 2022.
In 2022, Sam Bankman-Fried gave the LPP: $480k in April, $138k in May, and $700k in June.
In 2023, Dustin Moskowitz gave it: $34,000 in February, $170,000 in June, and $75,000 in August.
Jaan Tallinn donated $265,000 in 2021, $115,000 in 2022, and $103,000 in 2023.
AI analogies <without> policy implications
Essence: The nature of AI (what AI ‘is’)
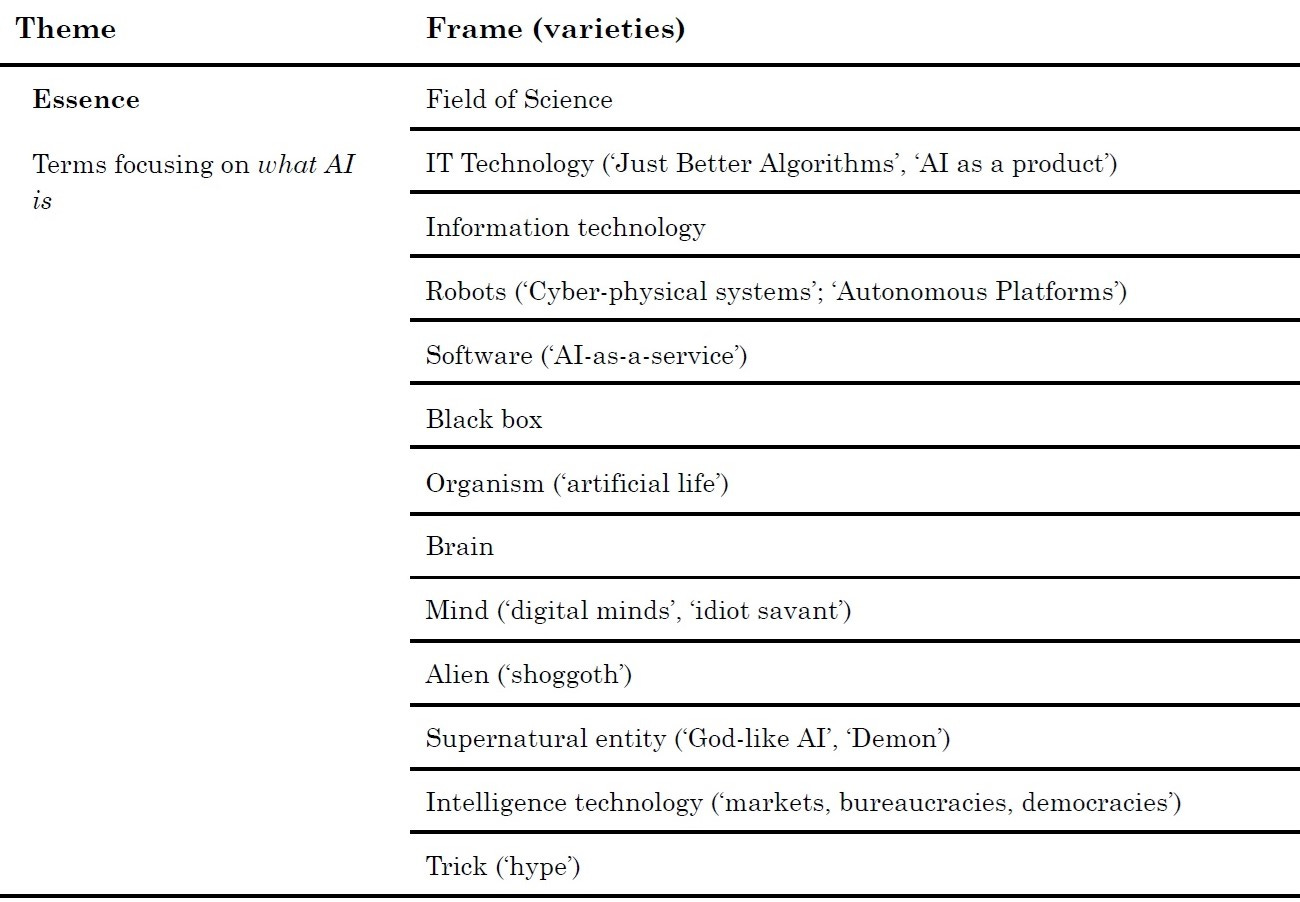
Operation: AI’s operation (how AI works)
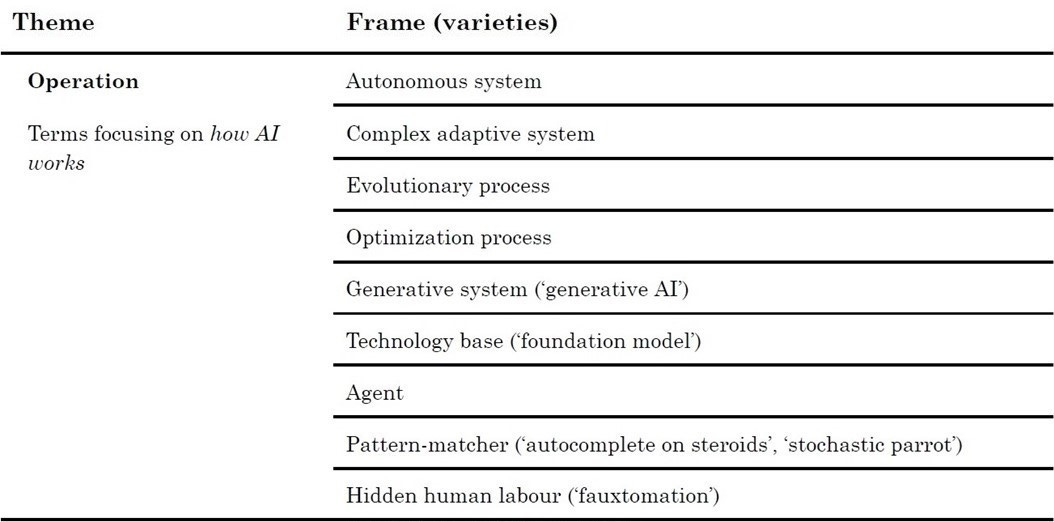
Relation: Our relation to AI (how we relate to AI as subject)
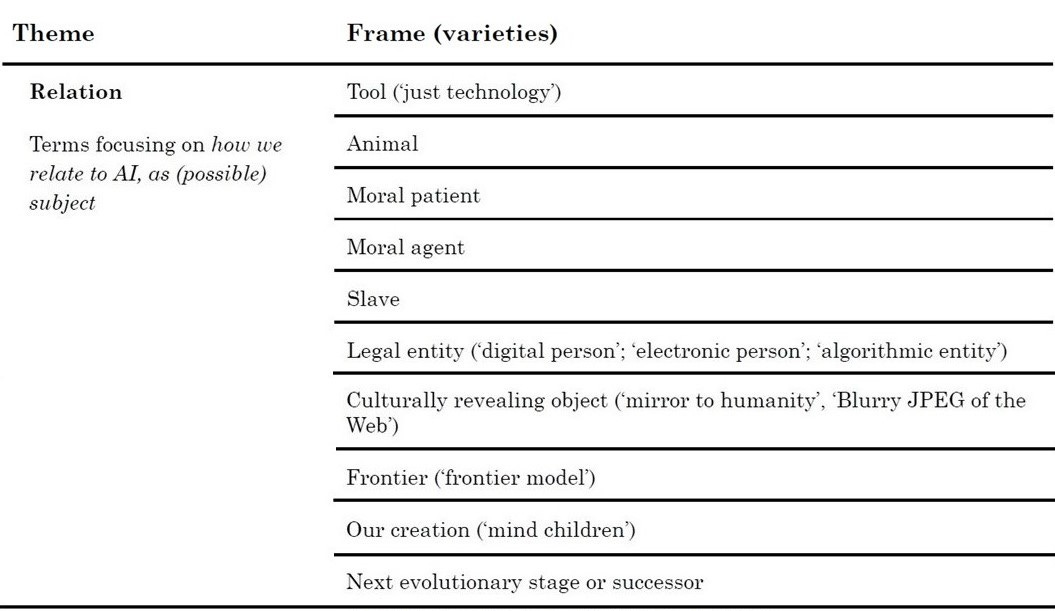
Function: AI’s societal function (how AI systems are or can be used)
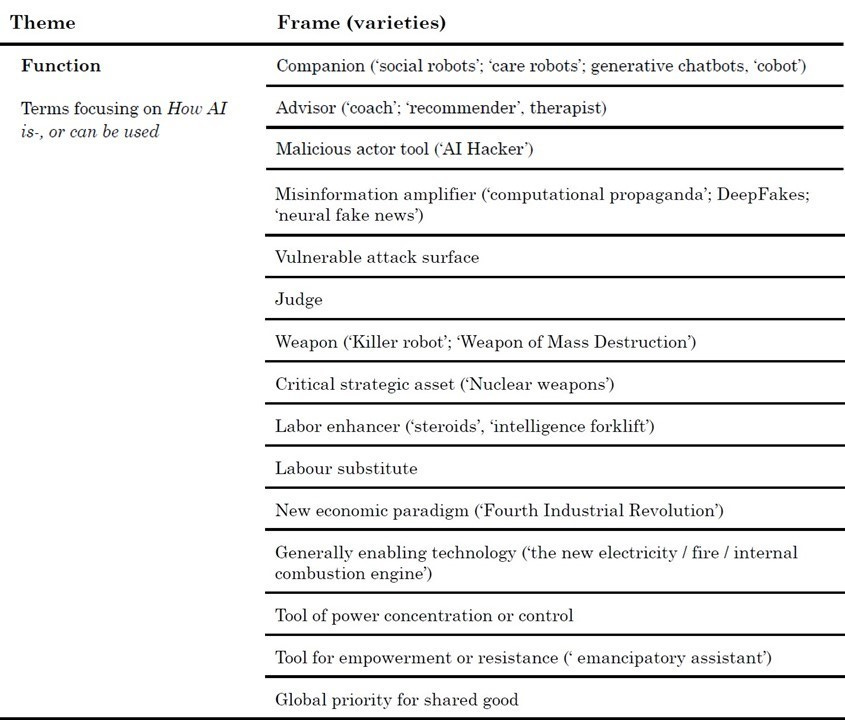
Impact: AI’s impact (the unintended risks, benefits, and other side-effects of AI)
Dan Hendrycks was one of the individuals Yoshua Bengio acknowledged (at the end of his paper). Hendrycks, the Center for AI Safety co-founder, initiated the second “AI x-risk” open letter aiming at a multinational regulation of AI development. Recently, he updated his AI Safety course with new materials. In it, he teaches about a power-seeking AI with self-preservation behavior.
He is also behind California’s controversial SB 1047 bill (currently in amendments).
Critics of this bill say, “Exceptional claims require exceptional evidence.” The “Superintelligence” philosophical thought experiment by Nick Bostrom is not evidence. See, for example, “Superintelligence: The idea that eats smart people” by Maciej Ceglowski.
These kinds of catastrophic scenarios result with depression and a need for mental health support. It’s crucial to listen to the testimonies of current doomers and ex-doomers. Other victims of the effective altruism movement contemplated suicide, had suicidal thoughts, or actually took their own lives (See Bloomberg’s The real-life consequences of Silicon Valley’s AI obsession: “Several people in Taylor’s sphere had similar psychotic episodes. One died by suicide in 2018 and another in 2021”).
The Machine Intelligence Research Institute (MIRI) wrote that the way to prevent future “misaligned smarter-than-human AI systems” is to shut down AI development completely. “We want humanity to wake up and take AI x-risk seriously. We do not want to shift the Overton window, we want to shatter it.” According to MIRI, policymakers need to “get it” and understand that AI will “kill EVERYONE, including their children,” because it's the … “central truth.” It’s best summed up by one of the reactions MIRI got on the LessWrong forum:

The quote is from Milton Mueller’s “The Myth of AGI: How the illusion of Artificial General Intelligence distorts and distracts digital governance.”
Additional recommended reading:
“Technology Fears and Scapegoats: 40 Myths about Privacy, Jobs, AI, and Today’s Innovation Economy” by Robert Atkinson and David Moschella.
“AI Snake Oil: What Artificial Intelligence Can Do, What It Can’t, and How to Tell the Difference” by Arvind Narayanan and Sayash Kapoor.